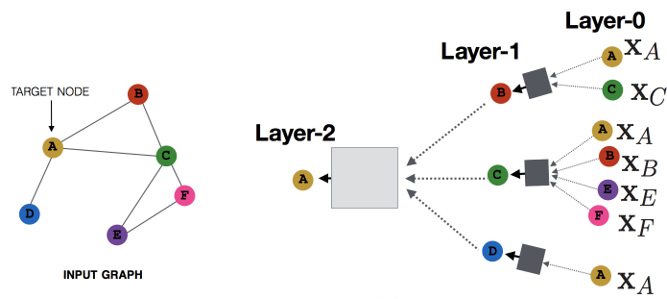
نمودار نمونه و جمع
MPNN روند جمع شدن فضایی را به خوبی جمع بندی می کند ، اما همه مدل های تعریف شده در این چارچوب دارای یک نقص مشترک هستند: هدف از عملیات کانولوشن کل تصویر است ، به این معنی که همه گره ها باید وارد شوند عملیات کانولوشن فقط در حافظه / حافظه فیلم. اما برای نمودارهای مقیاس بزرگ در صحنه های واقعی ، عمل جمع شدن روی کل نمودار واقع بینانه نیست. یکی از انگیزه های GraphSage حل این مشکل است. از نام این روش نیز می توان دریافت که ، متفاوت از کانولوشن سنتی نمودار کامل ، GraphSage از روش نمونه برداری از برخی از گره ها برای یادگیری استفاده می کند. البته ، حتی اگر کل نمودار به طور همزمان نیازی به جمع شدن نداشته باشد ، GraphSage باز هم نیاز به جمع آوری اطلاعات گره های همسایه ، یعنی عملیات کل تعریف شده در مقاله دارد . این عملیات مشابه فرآیند ارسال پیام در MPNN است .

به طور خاص ، روند نمونه گیری در GraphSage به سه مرحله تقسیم می شود:
- تعدادی از گره ها به طور تصادفی در نمودار نمونه برداری می شوند و تعداد گره ها در کار سنتی است batch_size. برای هر گره ، تعداد ثابتی از گره های همسایه به طور تصادفی انتخاب می شوند (در اینجا همسایگان لزوما همسایگان مرتبه اول نیستند ، بلکه همسایگان مرتبه دوم نیز هستند) تا گرافی برای عملکرد کانولوشن تشکیل شود.
- اطلاعات گره های همسایه را منتقل کنیدآggرهgآتیهتابع گره نمونه برداری شده را جمع و به روز می کند.
- ضرر را در گره نمونه گیری محاسبه کنید. اگر این یک کار بدون نظارت است ، امیدواریم که کدگذاری گره های همسایه روی نمودار مشابه باشد ؛ اگر یک کار نظارت شده باشد ، می توانیم ضرر را بر اساس برچسب کار گره خاص محاسبه کنیم.
سرانجام ، فرمول بروزرسانی وضعیت GraphSage به شرح زیر است:
ساعتvمن+1=σ(دبلیومن+1⋅آggرهgآتیه(ساعتvمن،{ساعتتومن})،∀توآnه[v])
تمرکز طراحی GraphSage روشن استآggرهgآتیهطراحی عملکرد این می تواند بدون پارامتر باشدمترآایکس، مترهآn، همچنین می تواند با پارامترهایی مانند باشدلستیممنتظر شبکه عصبی باشید. اصل اصلی همچنان وجود دارد که نیاز به توانایی مدیریت داده های با طول متغیر دارد. ReadOutعملیات برای کارهای نمودار در شبکه های عصبی کانولوشن ،آggرهgآتیهطراحی عملکرد مشابه آن است ، بنابراین من اینجا آن را توسعه نمی دهم.
 در این وبلاگ به ریاضیات و کاربردهای آن و تحقیقات در آنها پرداخته می شود. مطالب در این وبلاگ ترجمه سطحی و اولیه است و کامل نیست.در صورتی سوال یا نظری در زمینه ریاضیات دارید مطرح نمایید .در صورت امکان به آن می پردازم. من دوست دارم برای یافتن پاسخ به سوالات و حل پروژه های علمی با دیگران همکاری نمایم.در صورتی که شما هم بامن هم عقیده هستید با من تماس بگیرید.
در این وبلاگ به ریاضیات و کاربردهای آن و تحقیقات در آنها پرداخته می شود. مطالب در این وبلاگ ترجمه سطحی و اولیه است و کامل نیست.در صورتی سوال یا نظری در زمینه ریاضیات دارید مطرح نمایید .در صورت امکان به آن می پردازم. من دوست دارم برای یافتن پاسخ به سوالات و حل پروژه های علمی با دیگران همکاری نمایم.در صورتی که شما هم بامن هم عقیده هستید با من تماس بگیرید.